Funny Tinder Maker Her Laguh Reddit
I analyzed hundreds of user's Tinder data — including messages — so you don't have to.
The data is embarrassingly intimate but reveals the most boring parts of ourselves we already knew.

I read Modern Romance by Aziz Ansari in 2016 and beyond a shadow of a doubt, it is one of the most influential books I've ever read. At the time, I was a snot-nosed college student who was still dating someone from high school.
The numbers and figures given by the book about online dating success struck me as being callous. Millennials and their predecessors were blessed and cursed with the advent of the internet. The proliferation of partner-choice desensitizes us and gives us unrealistic expectations when it came to searching for our "soulmate."
Instead of feeling dissuaded, I felt inspired. Within a few months I broke up with my high school boyfriend and entered the online dating world myself. I quickly learned that dating is awful in it of itself, and it becomes exacerbated when it goes digital.
Tinder. Bumble. Hinge. CoffeeMeetsBagel. If it was on the App Store then I may have used it. Despite having mostly indifferent-to-underwhelming dating experiences, I couldn't shake this fascination I had with these godforsaken apps. I decided to channel that fascination as part of my final project for the Lede Program for Data Journalism at Columbia University.
Using nothing more than Python, Jupyter Notebook and frantic emails, I went head-first to create a project using dating app data.
1. Finding the data
Now that I had a project in mind, I needed to find the actual data. This was a huge hurdle.
First, I needed to choose an app to focus on. After browsing on r/dataisbeautiful for a few hours, I decided on Tinder due to its popularity.
I learned from Reddit and by reading other articles that I could request my own data. A few years ago, The Guardian wrote a story about how Tinder was using personal data. Part of the company's response was to make user data available upon request
Seems easy enough to do, right? Except, I didn't have any data to download. I had a habit of downloading Tinder to use for a few months before deleting my account out of frustration only to repeat the process.
I knew the data existed out there and despite the obstacles, I was determined to find it. After several rounds of googling "Tinder data" and coming up empty, I went back to Reddit. I noticed on r/dataisbeautiful that some people were visualizing their Tinder data using a website called Swipestats.io.
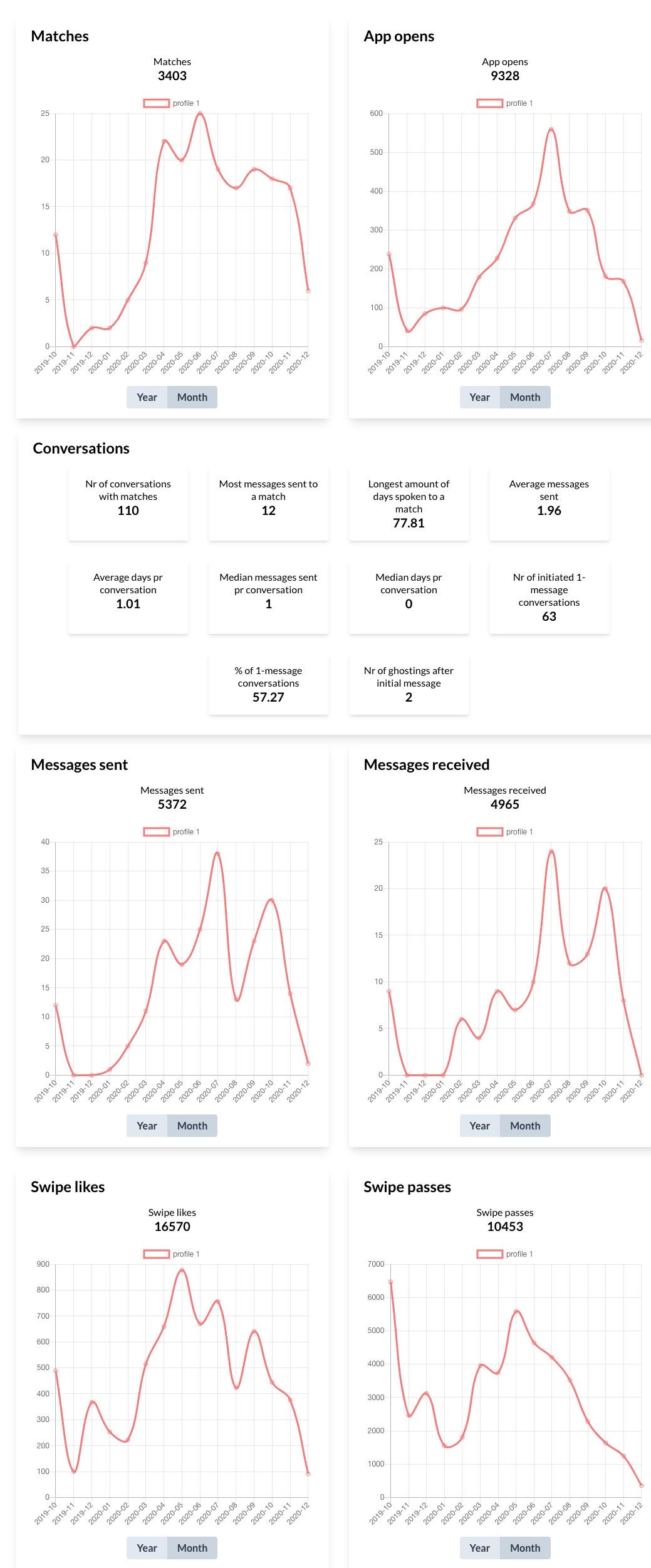
I decided to shoot my shot and send an email to the site's owner asking if he could share anonymous Tinder data with me for my project. He agreed (Thank you, Kris).
Next thing you know, I'm sitting on one JSON with 556 Tinder profiles.
2. Cleaning the data
This was a complete nightmare.
I've lost dozens of hours of my life not only trying to make sense of the data, but to clean it as well. By the end, I was in a very committed relationship with an overstuffed JSON.
The first obstacle I faced was figuring out how to open the file. It is big and whenever I tried to upload it to a notebook, I would get an error. I spoke with my mentor from the Lede Program (Thank you, Jeff) and he advised to run it through a JSON lint. I had no idea what that was.
I felt useless that I could barley open a large JSON. Things were looking bleak but I was hard-bent on creating a project using Tinder data.
Long story short, I converted the JSON into a .txt file then split the large .txt file into smaller ones using this site. By the miracle of some deity, the website split each .txt file perfectly by each person's file. Next, I converted the newly spit-up .txt files back into JSON format. Now I had a folder with 556 JSONs.
# Loading the data
import json f = open("user_x.json", encoding="utf-8")
data = json.load(f)
Finally, I was able to open my data. To my amazement, I noticed that messages were included.

I knew I had to prioritize and decided to focus on only three different objects, conversations, conversationsMeta and user. In the flowchart, I outlined the information in each object.
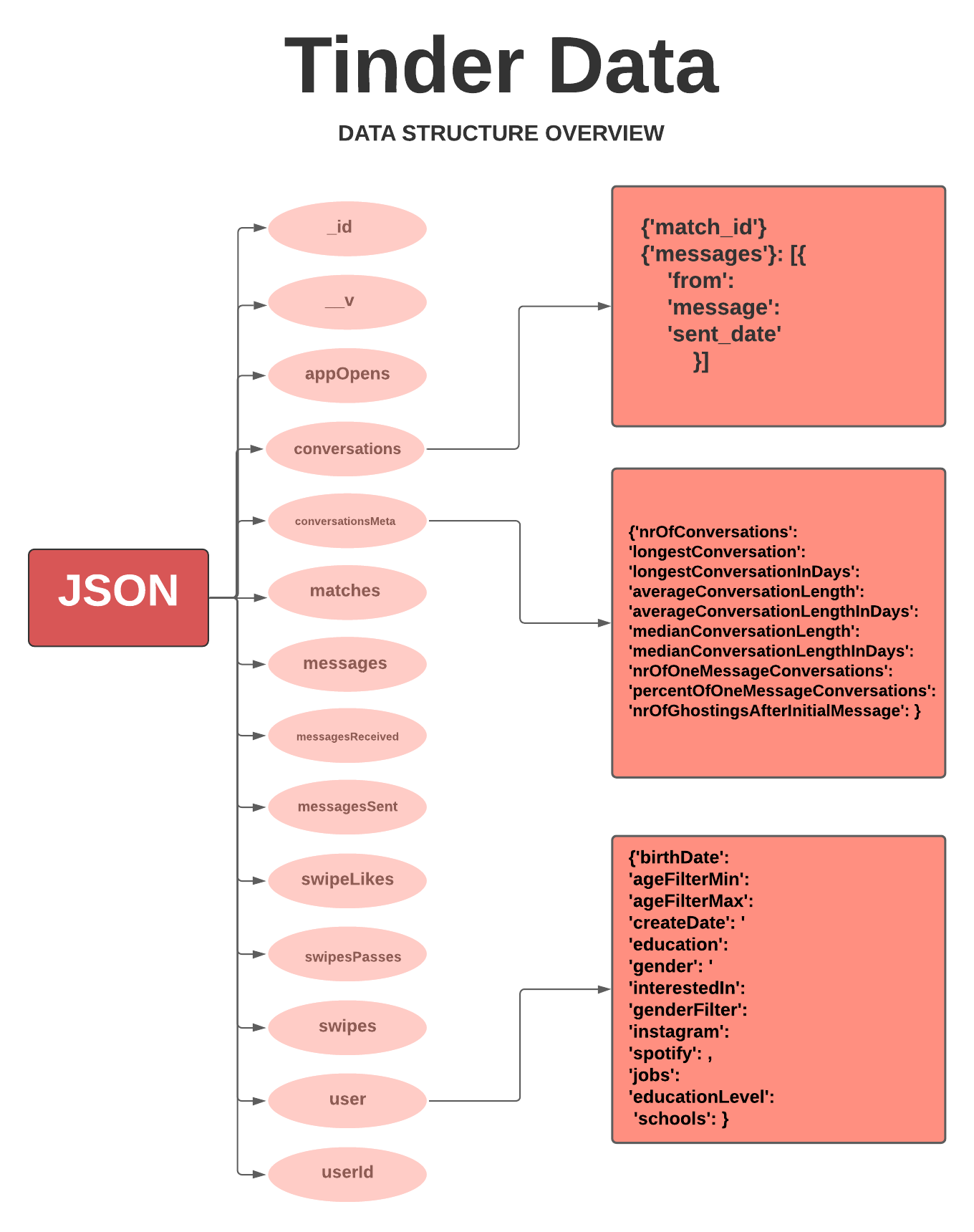
The possibilities were endless on what I could do, but I still wasn't done cleaning the data. The next obstacle was organizing it.
My next step was to organize the files by gender and language. A lot of the articles I read liked to compare men and women's experiences with dating, so I wanted to have those separate datasets. Additionally, I received quite an international set that was sprinkled in languages such as Japanese, Spanish, or German. As much as I appreciate the diversity, I only wanted to work with English profiles.
I had no idea where to start with organizing, so I went to office hours (Thank you, Thanasis). After a lot of head-scratching on Gather, we—mostly Thanasis— found a solution.
import shutil
import os
import glob
from os import path all_files = '/directory'
male = "/directory/MALE"
female = "/directory/FEMALE"
files = glob.glob(all_files+"/*.json")
for file in files:
with open(file, encoding="utf-8") as f:
data = json.load(f)
stat = data["user"]
for stats in stat:
if stat["gender"] == "M":
try:
shutil.move(os.path.join(all_files, file), male)
except:
pass
else:
try:
shutil.move(os.path.join(all_files, file), female)
except:
pass
This code simply moved a JSON to its respective folder whether it was male or female.
I tried to write a similar code to separate by language using TextBlob and langdetect. It didn't work. Out of pure spite, I separated the files by hand based on language.
By this point I'm feeling delirious but I'm almost at the end. My last step was to save the data into friendly CSVs, leaving me ~300 English-speaking data.
Saving conversations into CSV:
Note: The Tinder messages came with HTML tags. I included code to remove them below.
all_files = '/GENDER/ENGLISH'
files = glob.glob(all_files+"/*.json") # HTML parser code
from io import StringIO
from html.parser import HTMLParser class MLStripper(HTMLParser):
def __init__(self):
super().__init__()
self.reset()
self.strict = False
self.convert_charrefs= True
self.text = StringIO()
def handle_data(self, d):
self.text.write(d)
def get_data(self):
return self.text.getvalue() def strip_tags(html):
s = MLStripper()
s.feed(html)
return s.get_data() for file in files:
with open(file, encoding="utf-8") as q:
data = json.load(q)
all_convo = data["conversations"]
text = []
for message in all_convo:
for messages in message["messages"]:
messages["final_messages"] = ""
updated = messages["message"]
messages["final_messages"] = strip_tags(updated)
text.append(messages)with open('GENDER_convos.csv', 'a') as csvfile:
field_names = ['to', 'from', 'message', 'sent_date', 'final_messages']
writer = csv.DictWriter(csvfile, fieldnames=field_names, extrasaction='ignore')
writer.writeheader()
writer.writerows(text)
Saving conversationsMeta into CSV:
for file in files:
with open(file, encoding="utf-8") as q:
data = json.load(q)
user_data = []
user_data.append(data["conversationsMeta"])
field_names = ['nrOfConversations', 'longestConversation', 'longestConversationInDays',
'averageConversationLength', 'averageConversationLengthInDays',
'medianConversationLength', 'medianConversationLengthInDays',
'nrOfOneMessageConversations', 'percentOfOneMessageConversations',
'nrOfGhostingsAfterInitialMessage']
with open('GENDER_convometa.csv', 'a') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=field_names)
writer.writeheader()
writer.writerows(user_data) Saving user metadata into CSV:
for file in files:
with open(file, encoding="utf-8") as q:
data = json.load(q)
user_data = []
md = data["user"]
for job in md['jobs']:
if job['title'] == None:
pass
else:
md['jobs'] = job['title']
try:
for school in md['schools']:
if school['name'] == None:
pass
else:
md['schools'] = school['name']
except:
pass
user_data.append(md)
field_names = ['birthDate', 'ageFilterMin', 'ageFilterMax', 'cityName', 'country', 'createDate',
'education', 'gender', 'interestedIn', 'genderFilter', 'instagram', 'spotify', 'jobs',
'educationLevel', 'schools']
with open('GENDER_md.csv', 'a') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=field_names)
writer.writeheader()
writer.writerows(user_data) Is data ever completely cleaned? No. It's an endless task.
3. Analyzing the data
Before you get too excited, I need to admit that just about everything I found is kind of boring. I spent the vast majority of my time cleaning the data so this part is a little dull, especially considering that I'm writing this at 10:54 PM and am supposed to turn this in at 9:00 AM tomorrow.
You live and you learn.
I made an analysis based on the three CSVs made earlier. As a reminder, they each contain conversations, conversationsMeta and user metadata. The code is available here.
Side note: I was heavily influenced by this article from Data Drive that analyzed Tinder data made from bots. That article goes in much greater depth and uses substantially cleaner code.
A) Analyzing conversations
This was arguably the most tedious of all the datasets because it contains half a million Tinder messages. The downside is that Tinder only stores messages sent and not received.
The first thing I did with conversations was to create a language model to detect flirtation. The final product is rudimentary at best and can be read about here.
Moving forward, the first analysis I made was to discover what are the most commonly used words and emojis among users. In order to avoid crashing my computer, I used only 200,000 messages with an even mix of men and women.
So what are the top ten words?

Riveting.
To make it more exciting, I borrowed what Data Dive did and made a word cloud in the shape of the iconic Tinder flame after filtering out stop words.
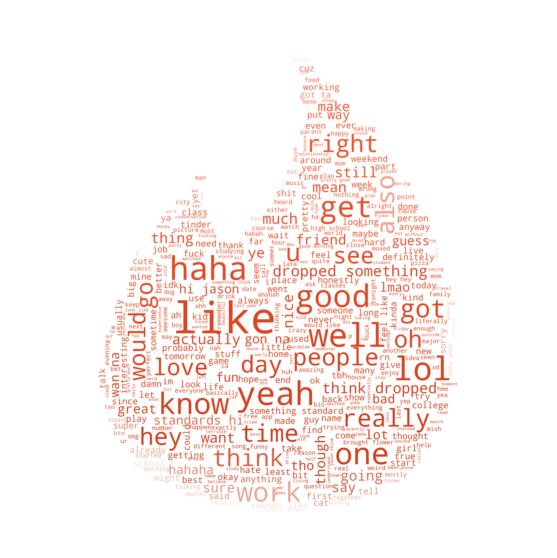
Yeah, yeah, yeah. Words are great— but what about emojis?
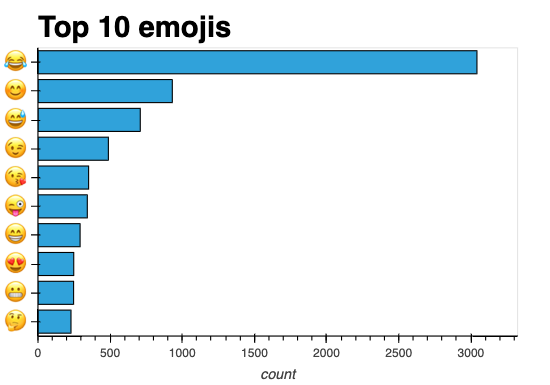
Fun fact: My biggest pet peeve is the laugh-cry emoji, otherwise known as : joy : in shortcode. I dislike it so much I won't even display it in this article outside of the graph. I vote to retire it immediately and indefinitely.
How much do these results vary by gender?

It seems that "like" is still the reining champion among both genders. Although, I think it's interesting how "hey" appears in the top ten for men but not women. Could it be because men are expected to initiate conversations? Possibly.
What about emoji comparisons?
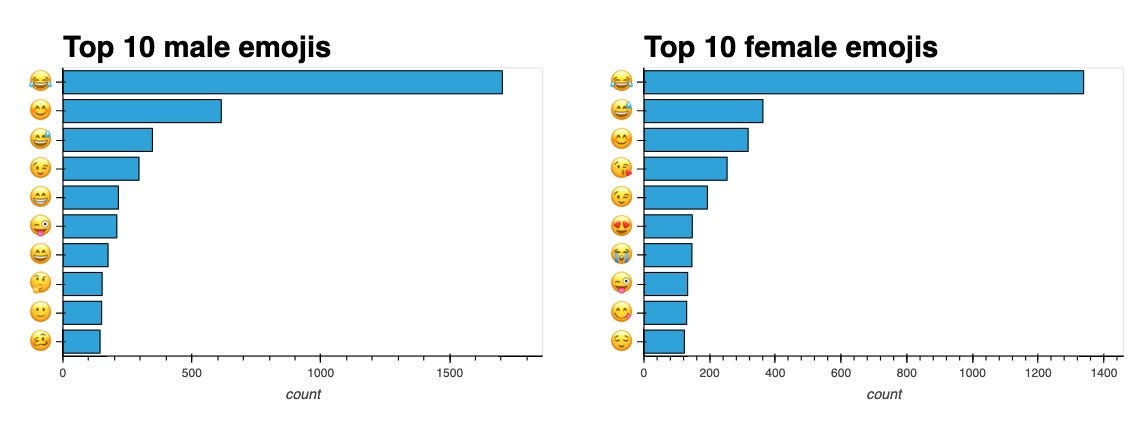
It seems that female users use flirtier emojis (😍, 😘) more often than male users. Still, I'm upset but not surprised that : joy : transcends gender when it comes to dominating the emoji charts.
B) Analyzing conversationsMeta
This portion was the most straightforward but could have also used the most elbow grease. For now, I used it to find averages.
These are the keys available in this dataframe:
['nrOfConversations', 'longestConversation', 'longestConversationInDays',
'averageConversationLength', 'averageConversationLengthInDays',
'medianConversationLength', 'medianConversationLengthInDays',
'nrOfOneMessageConversations', 'percentOfOneMessageConversations',
'nrOfGhostingsAfterInitialMessage', 'Sex']
The ones that stick out to me are nrOfConversations, nrOfOneMessageConversations and nrOfGhostingsAfterInitialMessage.
import pandas as pd
import numpy as np cmd = pd.read_csv('all_eng_convometa.csv') # Average number of conversations between both sexes
print("The average number of total Tinder conversations for both sexes is", cmd.nrOfConversations.mean().round()) # Average number of conversations separated by sex
print("The average number of total Tinder conversations for men is", cmd.nrOfConversations[cmd.Sex.str.contains("M")].mean().round())
print("The average number of total Tinder conversations for women is", cmd.nrOfConversations[cmd.Sex.str.contains("F")].mean().round())
The average number of total Tinder conversations for both sexes is 278.0.
The average number of total Tinder conversations for men is 218.0.
The average number of total Tinder conversations for women is 464.0.
Wow. The variation between men and women's Tinder experiences is felt here.
# Average number of one message conversations between both sexes
print("The average number of one message Tinder conversations for both sexes is", cmd.nrOfOneMessageConversations.mean().round()) # Average number of one message conversations separated by sex
print("The average number of one message Tinder conversations for men is", cmd.nrOfOneMessageConversations[cmd.Sex.str.contains("M")].mean().round())
print("The average number of one message Tinder conversations for women is", cmd.nrOfOneMessageConversations[cmd.Sex.str.contains("F")].mean().round())
The average number of one message Tinder conversations for both sexes is 80.0.
The average number of one message Tinder conversations for men is 74.0.
The average number of one message Tinder conversations for women is 99.0.
Interesting. Especially after seeing that, on average, women receive just over double the messages on Tinder I'm surprised that they have the most one message conversations. However, it isn't clarified who sent that first message. My guest is that it only reads when the user sends the first message since Tinder doesn't save received messages. Only Tinder can clarify.
# Average number of ghostings between each sex
print("The average number of ghostings after one message between both sexes is", cmd.nrOfGhostingsAfterInitialMessage.mean().round()) # Average number of ghostings separated by sex
print("The average number of ghostings after one message for men is", cmd.nrOfGhostingsAfterInitialMessage[cmd.Sex.str.contains("M")].mean().round())
print("The average number of ghostings after one message for women is", cmd.nrOfGhostingsAfterInitialMessage[cmd.Sex.str.contains("F")].mean().round())
The average number of ghostings after one message between both sexes is 50.0.
The average number of ghostings after one message for men is 18.0.
The average number of ghostings after one message for women is 151.0
Similar to what I brought up previously on nrOfOneMessageConversations, it isn't entirely clear who initiated the ghosting. I would be personally shocked if women were being ghosted more on Tinder.
C) Analyzing user metadata
Here are the objects available in the user metadata.
['birthDate', 'ageFilterMin', 'ageFilterMax', 'cityName', 'country',
'createDate', 'education', 'gender', 'interestedIn', 'genderFilter',
'instagram', 'spotify', 'jobs', 'educationLevel', 'schools']
I wanted to create an age column and decided that I could determine user age as (createDate - birthDate).
# CSV of updated_md has duplicates
md = md.drop_duplicates(keep=False) from datetime import datetime, date md['birthDate'] = pd.to_datetime(md.birthDate, format='%Y.%m.%d').dt.date
md['createDate'] = pd.to_datetime(md.createDate, format='%Y.%m.%d').dt.date md['Age'] = (md['createDate'] - md['birthDate'])/365
md['age'] = md['Age'].astype(str)
md['age'] = md['age'].str[:3]
md['age'] = md['age'].astype(int) # Dropping unnecessary columns
md = md.drop(columns = 'Age')
md = md.drop(columns= 'education')
md = md.drop(columns= 'educationLevel') # Rearranging columns
md = md[['gender', 'age', 'birthDate','createDate', 'jobs', 'schools', 'cityName', 'country',
'interestedIn', 'genderFilter', 'ageFilterMin', 'ageFilterMax','instagram',
'spotify']]
# Replaces empty list with NaN
md = md.mask(md.applymap(str).eq('[]')) # Converting age filter to integer
md['ageFilterMax'] = md['ageFilterMax'].astype(int)
md['ageFilterMin'] = md['ageFilterMin'].astype(int)
Next, I wanted to find the mean of age, ageFilterMax and ageFilterMin. I noticed that the numbers were skewed unusually high so I checked my dataset and noticed some trolling. I removed the following from the dataset.
One person who had their age at 106 and another at 137. Two people aged 16 and one listed as 15. I also removed 17 people who put 1000 as their ageFilterMax and one person who listed 95.
I discovered the following:
# Combined age data
print("The average user age for both genders is", all_age.age.mean().round()) print("The average user age filter maximum for both genders is", all_age.ageFilterMin.mean().round()) print("The average user age filter minimum for both genders is", all_age.ageFilterMax.mean().round()) print("--------------------") # By gender
print("The average male user age is", all_age.age[all_age.gender.str.contains("M")].mean().round()) print("The average female user age", all_age.age[all_age.gender.str.contains("F")].mean().round()) print("--------------------") print("The average male user age filter maximum is", all_age.ageFilterMax[all_age.gender.str.contains("M")].mean().round()) print("The average female user age filter maximum is", all_age.ageFilterMax[all_age.gender.str.contains("F")].mean().round()) print("--------------------") print("The average male user age filter minumum is", all_age.ageFilterMin[all_age.gender.str.contains("M")].mean().round()) print("The average female user age filter minumum is", all_age.ageFilterMin[all_age.gender.str.contains("F")].mean().round())
The average user age for both genders is 24.0
The average user age filter maximum for both genders is 21.0
The average user age filter minimum for both genders is 31.0
--------------------
The average male user age is 24.0
The average female user age 23.0
--------------------
The average male user age filter maximum is 31.0
The average female user age filter maximum is 32.0
--------------------
The average male user age filter minumum is 20.0
The average female user age filter minumum is 23.0
For added effect, I used this same data to make histograms.



Last, but certainly not least, I looked at jobs, schools, cities and country.
# Creating df of jobs listed
jobs_df = pd.DataFrame(md['jobs'].value_counts(dropna=True))
jobs_df.reset_index(level=0, inplace=True)
jobs_df = jobs_df.rename(columns={"index": "Jobs", "jobs": "Count"}) # Dropped index that said False
jobs_df = jobs_df.drop(0)
jobs_df = jobs_df.drop(1) jobs_df.head(10)

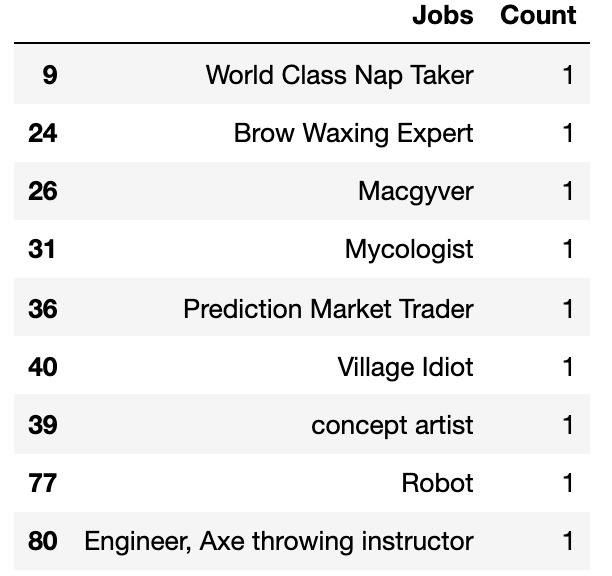
I know what you're thinking— boring, right? I went through the list myself and selected my favorites.
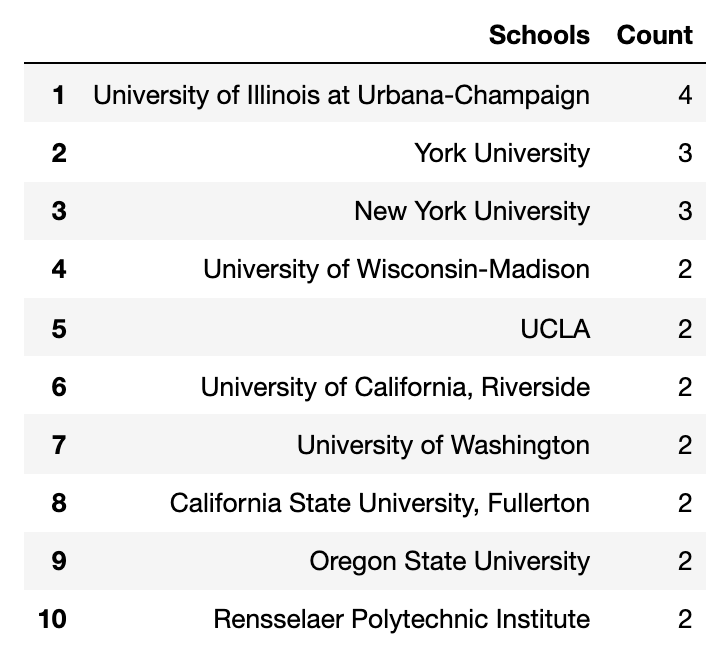
These are the top ten schools from the Tinder data.
# Creating df of schools listed
school_df = pd.DataFrame(md['schools'].value_counts(dropna=True))
school_df.reset_index(level=0, inplace=True)
school_df = school_df.rename(columns={"index": "Schools", "schools": "Count"}) # Dropped index that was empty list
school_df = school_df.drop(0) school_df.head(10)
Top ten cities based on the Tinder data.
# Creating df of cities listed
city_df = pd.DataFrame(md['cityName'].value_counts(dropna=True))
city_df.reset_index(level=0, inplace=True)
city_df = city_df.rename(columns={"index": "City", "cityName": "Count"}) city_df.head(10)

Finally, the top ten countries. However, Tinder grouped states and country together so its messy to say the least.
# Creating df of countries/states listed
country_df = pd.DataFrame(md['country'].value_counts(dropna=True))
country_df.reset_index(level=0, inplace=True)
country_df = country_df.rename(columns={"index": "Country/State", "country": "Count"}) country_df.head(10)

Final thoughts
All in all, the data is embarrassingly intimate but reveals the most boring parts of ourselves we already knew.
It was no surprise to discover that women on average have more conversations on Tinder than men or that : joy : is the most popular emoji used. Frankly, my findings are underwhelming but it's a start.
I see a lot of potential for future projects using this data and I hardly touched the surface. Ideas for the future include building a more reliable flirtation analysis tool or creating a Tinder message bot.
In either case, I'm excited for what's to come.
Acknowledgements
Thank you to Soma for not only being an excellent instructor but for spearheading the Lede program! Extra shoutouts for Carson, Thanasis, Jeff and Pete for helping me out.
And a special thank you to Swipestats.io for providing me with the data and can be contacted below.
Kristian Elset Bø
email: kristian@boe.ventures
LinkedIn: https://www.linkedin.com/in/kristianeboe/
Source: https://towardsdatascience.com/i-analyzed-hundreds-of-users-tinder-data-including-messages-so-you-dont-have-to-14c6dc4a5fdd
0 Response to "Funny Tinder Maker Her Laguh Reddit"
Enregistrer un commentaire